Deferred ACK in Apache Camel: Building a Reliable Batch Processing Pipeline with Pulsar



 Arpit Goyal
Arpit GoyalIntroduction
At Toast, we built a synchronization pipeline that processes real-time employee change events and syncs them to external partner systems — in this case, a customer's Learning Management System (LMS). The goal: when a restaurant hires, updates, or terminates an employee in Toast, that change automatically propagates to every connected tool so employee data stays consistent across systems.
Events flow through multiple integration points — gRPC services for enrichment, REST APIs for external data mapping, and email notifications when a mapping is incompatible or missing for an employee. We chose Apache Camel as our routing framework because it gave us aggregation, retry, and dead-letter queue handling out of the box. But using one of its most powerful features — batch aggregation — introduced a reliability challenge: how do we guarantee zero message loss when the default acknowledgment mechanism breaks down mid-pipeline?
This post covers the trade-off that came with batching, and the patterns we built to solve it — patterns we can apply in our own event-driven pipelines.
The Pipeline
Our pipeline processes two types of events:
Real-time events — employee changes (hired, updated, terminated) published to a Pulsar topic as Protobuf messages
Manual sync requests — on-demand re-sync of all employees for a given restaurant, triggered when external mapping data changes
Building and maintaining the routing, retry, batching, and failure handling for that chain ourselves would have been significant ongoing work. We chose Apache Camel because it solves all of that out of the box — aggregation, content-based routing, retry with backoff, and dead-letter queue handling are all first-class primitives. It is also a pattern used across Toast engineering teams, so the operational knowledge transfers.
One additional constraint shaped the design: our external integration has a rate limit on concurrent requests. Sending one API call per employee event would overload it at scale. We needed batch aggregation — collect N events, deduplicate, then make a single API call. That batching decision is what broke auto-ACK. The rest of this post is about how we solved that.
Pulsar Message
│
▼
Parse Protobuf + Filter (LaunchDarkly)
│
▼
Batch Aggregation + Deduplication
│
▼
gRPC Enrichment (toast-employees)
│
▼
External ID Resolution (entity-mapping-service)
│
▼
Email notification if required
│
▼
ACK / NACK
Why Batching Breaks Auto-ACK
In a simple Camel + Pulsar route with no aggregation, acknowledging a message is straightforward. Camel automatically ACKs the message once the exchange completes successfully. The exchange is the same object from start to finish, so the framework always has a reference back to the original Pulsar message.
With aggregation, Camel merges N input exchanges into one output exchange. The original exchanges are destroyed. The Pulsar message receipt — stored in the exchange header disappears with them.
// This works BEFORE aggregation
val receipt = exchange.getIn()
.getHeader("message_receipt", PulsarMessageReceipt::class.java)
// This returns null AFTER aggregation — the original exchange is gone
If we try to ACK after an aggregation step using the standard Camel Pulsar mechanisms, we are operating on an exchange that has no connection to any original Pulsar message. The ACK silently does nothing, and Pulsar redelivers all messages after ackTimeoutMillis. We needed a different approach: preserve the pulsar message receipts ourselves, carry them through every transformation, and ACK them manually at the end.
Why Not Simply Avoid Batching?
Before committing to the deferred ACK pattern, we considered the simpler alternative — processing each message individually without aggregation. This would have kept the default auto-ACK behaviour intact and avoided the receipt preservation complexity entirely.
However batching is not just an optimisation here — it is a hard requirement for two reasons. First, downstream services like our gRPC enrichment service expose batch APIs specifically because per-message calls at scale create significant spike load. Second, every external partner integration comes with its own rate limits, and different partners have different thresholds. Sending one API call per employee event would breach those limits at any meaningful scale.
Beyond that, batching improves throughput by amortising the fixed cost of each network call across multiple messages, and collapses duplicate events for the same employee into a single outbound call with the latest state — avoiding redundant processing downstream.
Finally, manual deferred ACK gave us precise control over acknowledgment that auto-ACK cannot provide — ACKing only after every processor has successfully completed, and NACKing precisely the messages that failed. Batching was unavoidable. The question then became: how do we make it reliable?
Solution: Receipt Preservation Through the Pipeline
The solution has three parts.
Part 1 — Extract and Embed Before Aggregation
The Camel Pulsar component places the message receipt in the exchange header when a message arrives. The key insight is to extract it at the earliest possible point, before the aggregator ever sees the exchange and embed it directly into our domain model as a field.
// In event processor, before aggregation runs
val receipt = exchange.getIn()
.getHeader("message_receipt", PulsarMessageReceipt::class.java)
val event = EmployeeSyncEnvelope(
id = parsedMessage.id,
payload = parsedMessage.payload,
receipt = receipt // receipt now lives on the domain object, not the exchange
)
exchange.getIn().body = event
This way, when Camel's aggregator destroys the exchange, the receipt travels with our data object rather than disappearing with the exchange headers. Note that EmployeeSyncEnvelope is not a core business object — it is a lightweight pipeline envelope purpose-built to carry both the business data and the messaging receipt together through the route. Core business objects like Employee or Order should stay free of infrastructure concerns like receipts.
Part 2 — Accumulate Receipts Inside the Aggregation Strategy
Extracting the receipt into our domain model in Part 1 solves half the problem. This part is making sure those receipts are collected in one place after the batch is assembled, ready to be tracked through the rest of the pipeline. Inside our AggregationStrategy, as each new exchange comes in and gets merged into the growing batch, explicitly pull the receipt off the incoming event and append it to a shared list on the aggregated exchange body.
// Inside AggregationStrategy.aggregate()
val incomingEvent = newExchange.getIn().getBody(EmployeeSyncEnvelope::class.java)
// Collect receipt from every incoming message into one list
allReceipts.add(incomingEvent.receipt)
// Continue building aggregated batch data
// ...
aggregatedExchange.getIn().body = mapOf(
"events" to aggregatedEvents,
"receipts" to allReceipts
)
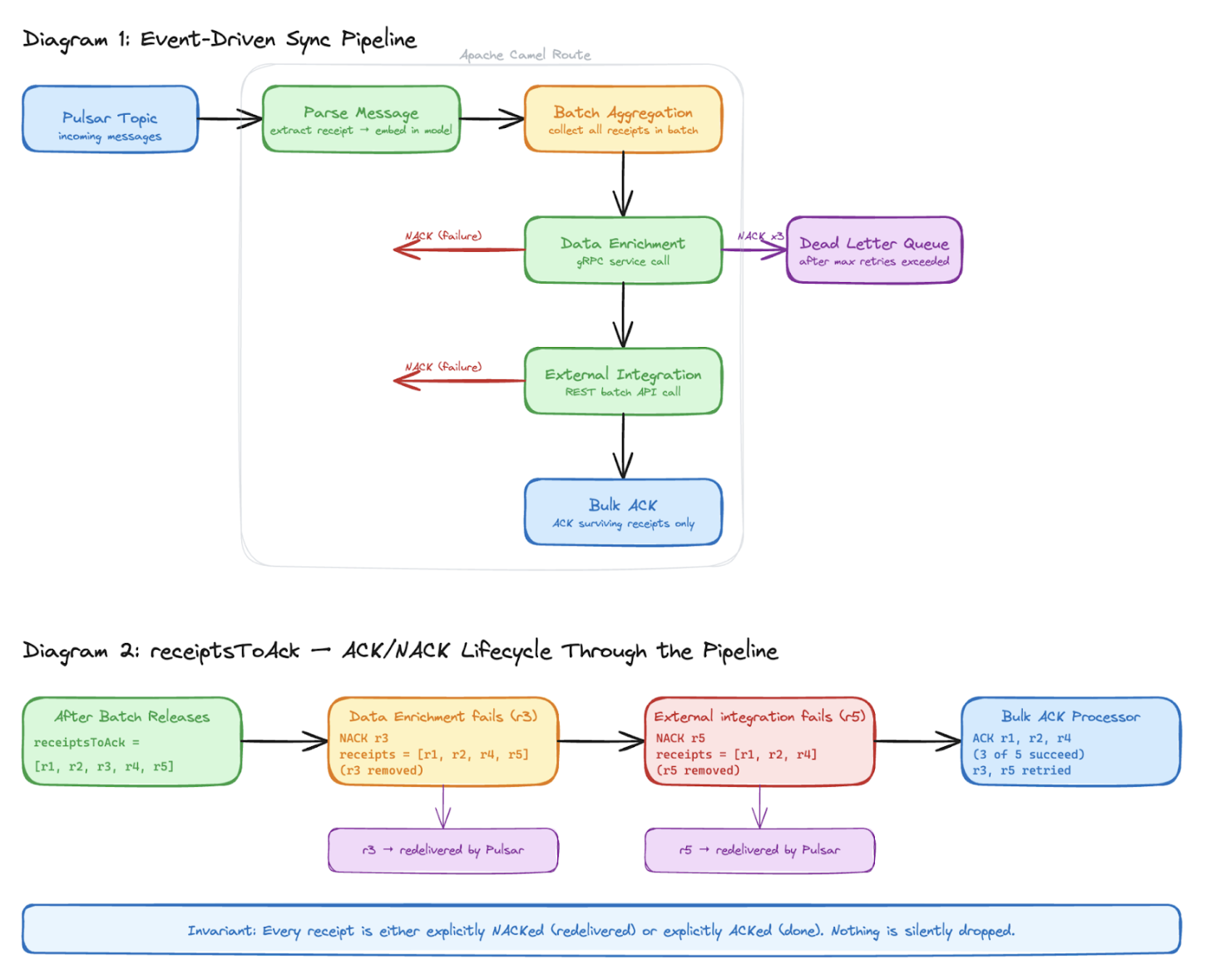
By the time the batch releases, whether by size limit or timeout we have a single, complete list of every receipt for every message that contributed to that batch. That list becomes the pipeline's source of truth for acknowledgment from this point forward.
Part 3 — Transfer to a Mutable Exchange Property
Once the batch releases, the receipt list is still buried inside the aggregated exchange body. The final setup step is to move it out into a dedicated exchange property — a mutable list that every downstream processor can independently read and modify.
// After batch releases, promote receipts to a trackable property
val allReceipts = (exchange.getIn().body as Map<*, *>)["receipts"] as Listexchange.setProperty("receiptsToAck", allReceipts.toMutableList())Say a batch of 5 messages arrives — [r1, r2, r3, r4, r5]. At this point, all five receipts sit in receiptsToAck. As the batch moves through the pipeline, each stage independently handles its own failures:
After batch releases: receiptsToAck = [r1, r2, r3, r4, r5]
gRPC enrichment fails for one employee: NACK r3 → receiptsToAck = [r1, r2, r4, r5]
External integration fails for another employee: NACK r5 → receiptsToAck = [r1, r2, r4]
Final ACK processor: ACKs r1, r2, r4
This single property becomes the pipeline-wide contract. Every processor that runs after this point follows one simple rule that if the work for a message succeeded, leave its receipt in the list and if it failed, remove it. The final processor ACKs whatever is left. The reason it needs to be mutable is intentional as each stage in the pipeline owns its own failures independently, shrinking the list as it goes, without needing to know what happened before or after it.
The key edge this gives: a message that passes gRPC enrichment successfully can still fail at the external integration step and vice versa. ACKing early would permanently mark a message as done before it has actually finished the pipeline. By deferring the ACK to the very end and NACKing immediately at the point of failure, each message is only ever acknowledged once it has successfully cleared every stage and only the employee that failed gets retried, not the entire batch.
At-Least-Once Delivery: How We Handle Redelivery
This pattern guarantees at-least-once delivery. In the event of a network failure or a transient error, a NACKed message will be redelivered and processed again. We handle this in two ways: our external integration is idempotent — re-sending the same employee record is safe and produces the same result. For the email notification path, the DLQ cap of 3 retries bounds the worst case — a message can trigger at most 3 notifications before it is quarantined for manual review.
The Timeout Math
There is a non-obvious timing constraint that must hold for this entire system to work correctly. Pulsar has an ackTimeoutMillis setting — if a consumed message is not ACKed within that window, Pulsar assumes the consumer died and redelivers it. This is normally useful. But with batch aggregation, messages sit in the aggregation window intentionally, waiting for the batch to fill or the timeout to fire.
If ackTimeoutMillis is shorter than our batch window, Pulsar redelivers messages while they are still being aggregated. The same message appears in two batches, causing unnecessary reprocessing.
ackTimeoutMillis: 1200000 # 20 minutes
maxWaitTimeMs: 600000 # 10 minutes — max batch windowA batch is triggered when either the message count limit is reached or the time limit expires — whichever comes first. We sized ackTimeoutMillis at 20 minutes based on the maximum batch window — the longest a message could sit in the aggregation window before the batch is triggered. The ackTimeoutMillis must always exceed this maximum wait time to ensure Pulsar does not redeliver messages that are still sitting in the aggregation window.
The trade-off is recovery time: if a consumer crashes mid-batch, Pulsar will not redeliver those messages for up to 20 minutes. We accepted the slower recovery because partial failures are far more common than full consumer crashes in practice. ackTimeout > batchWindow is a hard system invariant. We enforce this in configuration review and document it explicitly for every consumer we add.
Lessons Learned
Never rely on exchange headers surviving aggregation. Embed any metadata we need post-aggregation — receipts, correlation IDs, timestamps — directly into a pipeline-specific model before the aggregator runs. This does not mean putting infrastructure concerns like message receipts onto our core business domain objects. Instead, create a lightweight wrapper or envelope model purpose-built for the pipeline — one that carries both the business data and the messaging metadata together through the route. In our case EmployeeSyncEnvelope is not a business domain object; it is a pipeline model whose sole job is to carry an employee change event and its associated Pulsar receipt through the aggregation boundary together.
A mutable receipt list is a simple, auditable tracking primitive. Rather than trying to coordinate ACK/NACK across processors with callbacks or flags, a single receiptsToAck property that shrinks as failures occur gives every processor a self-contained, side-effect-free way to participate in the ACK strategy.
Design for partial failure from the start. In a multi-step pipeline, assuming all-or-nothing failure is optimistic. Building selective NACK — where one message's failure does not penalize the entire batch is worth the upfront design cost.
Conclusion
Building a reliable event-driven pipeline is rarely about any single decision , it's about a chain of small, deliberate choices that compound into a system we can trust at scale. The shift from auto-ACK to deferred manual ACK forced us to think differently about message ownership. Instead of letting the framework handle acknowledgment automatically, we took explicit control: extract the receipt early, carry it through every transformation, track it as a first-class object across the pipeline, and only release it when we were certain the message had been fully processed. The result is a pipeline where every message has a clear, traceable fate. Failures are isolated i.e a single employee failing enrichment does not penalize the rest of the batch. Retries are precise i.e only the message that failed is redelivered, not the entire batch. And the invariant is simple enough to reason about: every receipt is either ACKed or NACKed, nothing is ever silently lost.
____________________________
This content is for informational purposes only and not as a binding commitment. Please do not rely on this information in making any purchasing or investment decisions. The development, release and timing of any products, features or functionality remain at the sole discretion of Toast, and are subject to change. Toast assumes no obligation to update any forward-looking statements contained in this document as a result of new information, future events or otherwise. Because roadmap items can change at any time, make your purchasing decisions based on currently available goods, services, and technology. Toast does not warrant the accuracy or completeness of any information, text, graphics, links, or other items contained within this content. Toast does not guarantee you will achieve any specific results if you follow any advice herein. It may be advisable for you to consult with a professional such as a lawyer, accountant, or business advisor for advice specific to your situation.